Reading External Data into Pandas


In our previous abstract, we know how to read a CSV or Flat file into Pandas. Let's start with reading sheets in an excel file, JSON file etc. So what is Excel? In brief, Excel is a spreadsheet application that is a facilely accessible implement to organise, analyse, and store data in tables. It is widely utilised in many different applications all over the world. The popularity of Excel is due to its wide range of applications in the field of data storage and processing in tabular and systematic formats. In addition, Excel spreadsheets are so intuitive and easy to use that even non-technical people are ideal for working with large datasets.
Read an Excel File:
We can easily read an Excel file into Python by using the Pandas library. To accomplish this goal, we use read_excel(). Before this first import the pandas' library: import pandas as pd
Syntax: read_excel (‘file path of the excel file\excelfile.xlsx’, <arguments>)
Important arguments available:
sheet_name– int, str, list, or none, default 0
Strings are used for sheet names. Integers are used in zero-indexed sheet positions. Lists of strings/integers are used to request multiple sheets. Specify None to get all sheets.
Available cases:
Defaults to 0 : 1st sheet as a DataFrame
1 : 2nd sheet as a DataFrame
"Sheet1": Load sheet with name "Sheet1"
[0, 1," Sheet3"] : 1st, 2nd & sheet named "Sheet5" as a dictionary of DataFrames
None : all sheets as a dictionary of DataFrames
header: int, list of ints, default 0
The row (0-indexed) is used for the column label of the parsed DataFrame. If a list of integers is transferred, the positions of these rows are combined into a "MultiIndex". Use None if there is no header.
names : array-like, default None
List of column names to use. If the file contains no header row, then you should explicitly pass
header=None.
For more: https://pandas.pydata.org/docs/reference/api/pandas.read_excel.html#pandas.read_excel
Example:
Let's suppose our excel file has two sheets and looks like:
sheet rate
As shown below, we can now import this Excel file into the panda using the read_excel function.
The above line of code read the data from the statewise_total_pandas excel file and stores it in the pandas' data frame variable named covid_df (user-defined name). As we can see, if there are multiple sheets in the excel workbook, this code will import the data from the first sheet by default. The easiest way to create a data frame with all sheets in the workbook is to create different data frames individually and then concatenate them. The read_excel () method takes argument sheet_name and index_col to specify the sheets that make up the data frame, and index_col specifies the title column(by default, it will take the 0th index as the title of the column).
In the above code (In[18]), the third statement concatenates both the sheets (Sheet1, Sheet2). We can simply run the stored data frame named 'df' in the fourth line to check the whole data frame.
Read a JSON file:
The JSON format is nothing but JavaScript Object Notation which was originally inspired by JavaScript Programming Language(the programming language used for web development) but uses conventions from Python and many other languages outside of Python. It is a data-interchange, text-serialisation, language-independent data format and most of the programming languages that we use can create and read a JSON file. JSON is primarily used to store unstructured data, and SQL databases have a tough time storing it. JSON allows the machine to read the data.
There is a read_json ()function to read the JSON file. This function converts a JSON string to a Pandas object.
Syntax: read_json(path_or_buf=None, <other options>)
path_or_buf : a valid JSON str, path object or file-like object, Default: None
Any valid string path is acceptable. The string could be a URL(including HTTP, FTP, s3, file, etc.).
other options: For other options, please have a look into :
https://pandas.pydata.org/docs/reference/api/pandas.read_json.html
Example:
Now let's see how to load JSON data. The JSON dataset is from a link. Here the data is in a key-value dictionary format. There are a total of four keys: title, year, cast and genres.
First, import the Pandas library and then pass the URL to pd.read_json (), which returns a data frame. The data frame columns represent the keys, and the rows are the JSON values.

Read from HTML files:
HTML is a hypertext markup language used primarily for building web applications and pages. It endeavours to describe the structure of the web page semantically. The web browser receives the HTML files from the webserver and renders it a multimedia web page. HTML with cascading style sheets (CSS) is used for web applications, but it is used by various web servers frameworks such as Flask and Django on the server-side.
To read the HTML file, the pandas dataframe looks for the tag <td> </td> which is used to define a table in HTML.
pandas uses read_html() command to read the HTML document.
Whenever you pass HTML to Pandas and expect it to output an accurate data frame, ensure your HTML page contains a table.
Syntax: read_html(path, <other options>)
Inside read_html(), we will give the path of the HTML link. The read_html() function will return a list of data frames where each element in that list is a table (data frame).
For other options, please read the documentation:
https://pandas.pydata.org/docs/reference/api/pandas.read_html.html
Example:
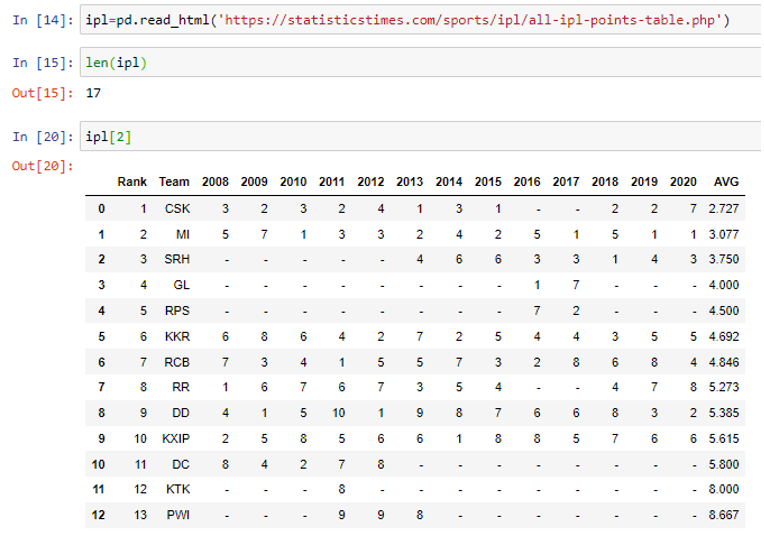
We are taking data from statisticstimes.com IPL data from the below link. Here there are 17 data frames available on the HTML page, and we are analysing the third data frame :



